Les données manquantes
Les données manquantes sont un problème à considérer dès la conception des modèles de données. En effet ne pas prendre en compte ce problème pourrait enttrâiner des problèmes inattendus lors des traitements, mais aussi des risques d'incohérences et d'ambiguïtés.
Données manquantes : des raisons multiples
D'après SPARC, les données pourraient être manquantes pour plusieurs raisons :
- L'information est applicable, mais la valeur n'est pas connue. Exemple : Date de décès d'une personne vivante
- L'information est inapplicable : Exemple : Nombre de sommets d'un cercle
- L'information existe, mais il n'est pas permis (légalement) de l'enregistrer : Exemple : Religion d'un employé
- ...
Le problème que l'on voit apparaître est la pluralité de raisons. On pourrait considéré deux raisons, qui engoublent plusieurs sous raisosn, pour lesquels un raison un attribut est annulable :
- L'attribut est non applicable à l'entrée.
- La valeur est applicable mais inconnue pour l'instant.
En SQL, le choix a été fait de marquer certains attributs à l’aide de la valeur spéciale NULL. Ce marquage a suscité de nombreuses recherches et nécessite une adaptation du modèle relationnel. En particulier, cela implique une modification de la logique utilisée dans les opérations. Selon le nombre de marquages possibles, on peut recourir à une logique à trois voire quatre valeurs (dans le cas d’un ou deux types de marquage).
Les logiques à 3 valeurs utilisées par SQL.
En SQL en fonction du contexte, la logique à 3 valeurs utilisés varient.
Logique à 3 valeurs utilisées dans CHECK
Satisfait si et seulement si (true ou unknown)
Opérateur OR
OR | true | unknown | false |
|---|---|---|---|
| true | true | true | true |
| unknown | true | unknown | unknown |
| false | true | unknown | false |
Opérateur AND
AND | true | unknown | false |
|---|---|---|---|
| true | true | unknown | false |
| unknown | unknown | unknown | false |
| false | false | false | false |
Logique à valeurs utilisées dans WHERE
Satisfait si et seulement si true
Opérateur OR
OR | true | unknown | false |
|---|---|---|---|
| true | true | unknown | true |
| unknown | unknown | unknown | unknown |
| false | true | unknown | false |
Opérateur AND
AND | true | unknown | false |
|---|---|---|---|
| true | true | unknown | false |
| unknown | unknown | unknown | false |
| false | false | unknown | false |
Résoudre par la conception
Pour éviter les problèmes liés aux données manquantes, nous agissons dès la phase de conception du modèle de données. Pour cela, nous appliquons des méthodes de décomposition afin d’éliminer l’annulabilité dans le modèle de données ainsi que d’identifier la cause du manque d’une donnée. Les décompositions utilisées sont :
- Les décompositions Projection-Jointure (DPJ)
- Les décompositions Restriction-Union (DRU)
Décomposition Projection-Jointure
La décomposition projection-jointure permet de séparer une relation en plusieurs relations plus petites. Dans le cas des données manquantes, cela permet d’isoler les attributs qui peuvent ne pas être renseignés. Cette approche présente également l’avantage de réduire les redondances dans le modèle de données.
Application de la décomposition Projection-Jointure
Dans la table suivante, nous voyons le modèle de données qui permet de représenter unÉtudiantdans le cadre de la gestion des stages :
| Étudiant |
|---|
| identifiant |
| nom |
| entreprise |
| durée |
Parmi les attributs de la table
Étudiant, certains ne sont pas disponibles immédiatement. En effet,entrepriseetduréene pourront être renseignés que lorsque l'étudiant aura trouvé un stage.La décomposition Projection-Jointure permet de décomposer cette table afin de ne pas avoir d'attribut annulable. On crée une table
Stage_Étudiantpour y renseigner uniquement les informations connues :
| Stage_Étudiant |
|---|
| identifiant_étudiant |
| entreprise |
| durée |
Une fois que les informations de stage sont connues, une entrée est ajoutée dans cette table. Les étudiants sans stage ne sont pas présents dans cette table.
Cependant, cette décomposition ne répond pas à la question : Pourquoi une donnée est-elle manquante ?
Décomposition Restriction-Union
Pour répondre à cette question, on utilise la décomposition Restriction-Union. Elle permet de classer les informations en plusieurs relations, que l'on peut ensuite regrouper par union.
Application de la décomposition Restriction-Union
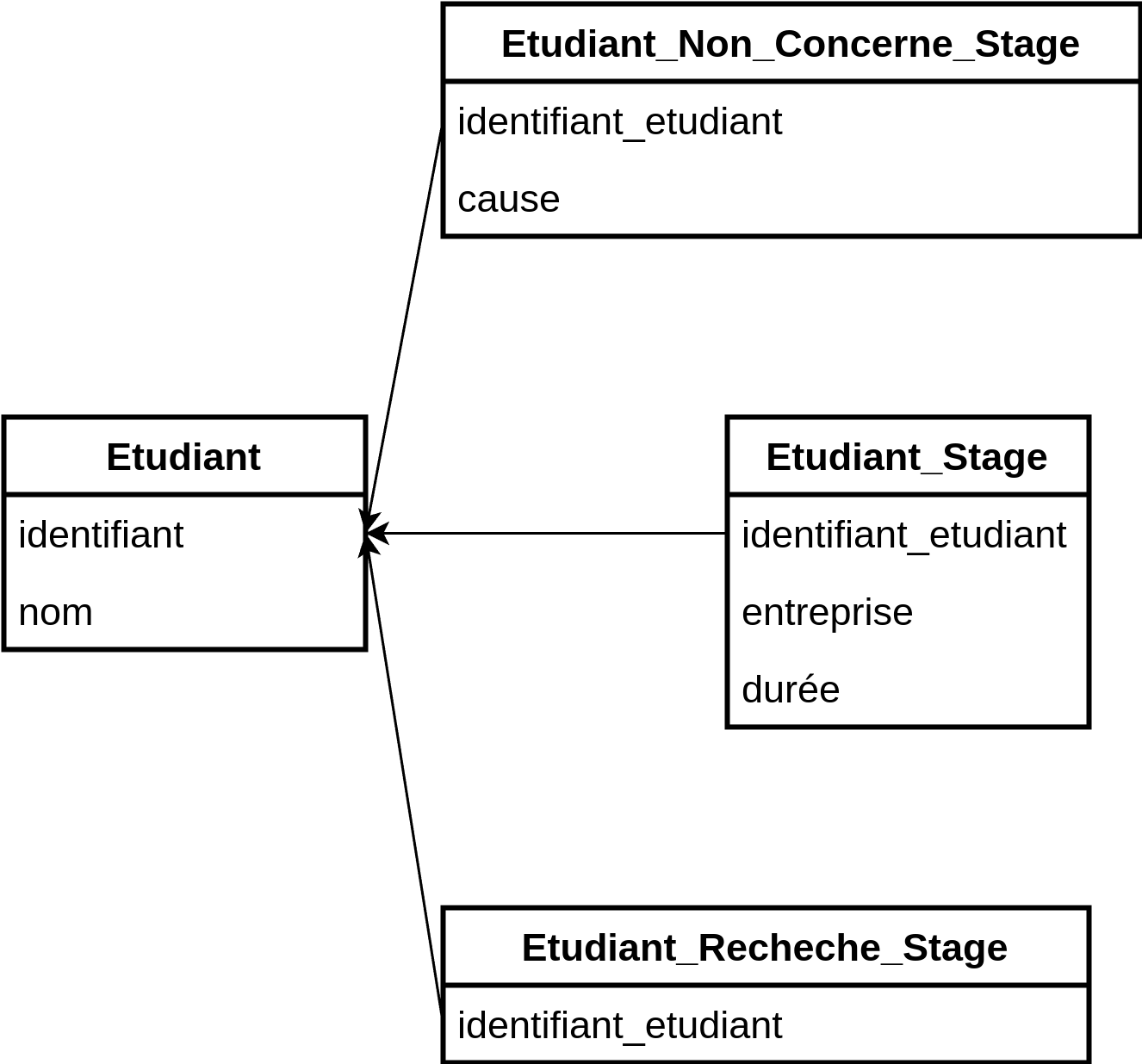
Pour expliciter pourquoi certains étudiants ont un stage et d'autres non, on peut créer plusieurs tables :
Étudiant_En_Recherche_StageÉtudiant_Ayant_Un_StageÉtudiant_Non_Concerné_Par_Un_Stage
L’union de ces trois tables permet d’obtenir l’ensemble des étudiants.
On peut aussi ajouter un attributcauseàÉtudiant_Non_Concerne_Par_Un_Stagepour expliciter pourquoi l’étudiant est dans cette table.
Il faut alors ajouter une contrainte pour éviter les doublons :
Solution : Décomposition Projection-Jointure et Restriction-Union
Pour traiter les données manquantes, la solution complète consiste à combiner les deux décompositions :
- Décomposition Projection-Jointure : structure sans annulabilité.
- Décomposition Restriction-Union : documentation de la cause des données manquantes.
Dans notre exemple, la table initiale Étudiant est décomposée en 4 tables :
Étudiant_StageÉtudiant_Recherche_StageÉtudiant_Non_Concerne_StageStage_Étudiant
La contrainte suivante doit être respectée :